Table of Contents
TL; DR
In the last six months of 2020, I read 214 children’s books from the library with my daughters. The gmailr and httr packages, and the Google Books API, allowed me to create a catalog of the books we read with preview images. You can skip straight to the books, or read on for code that follows these main steps with their primary packages.
Background
I live in Doylestown, PA (Bucks County), with my husband and two daughters (2 and 5 years old). On March 14, 2020, the Bucks County library system closed due to COVID-19; on June 22, 2020, the library opened with curbside pick-up service. Every one to two weeks, I began to place children’s books on hold (up to 15 at a time), and when a hold arrives, I receive an email notice like this:

Email notifications are sent around midnight, collating any books that arrived that day. As the email notifications trickled in and patterns emerged, I conceptualized a project to programmatically create a catalog of the library books we had placed on hold by extracting the books from my gmail and then augmenting their information from an API.
Getting started
This material was developed using:
| Software / package | Version |
|---|---|
| R | 4.0.3 |
| RStudio | 1.3.1073 |
tidyverse |
1.3.0 |
gmailr |
1.0.0 |
httr |
1.4.2 |
lubridate |
1.7.8 |
gt |
0.2.2 |
glue |
1.4.1 |
DT |
0.15 |
library(tidyverse) # general use ----
library(gmailr) # retrieve emails ----
library(httr) # access api ----
library(lubridate) # repair dates ----
library(gt) # for web_image helper function ----
library(glue) # paste strings ----
library(DT) # interactive table ---- 1 {gmailr} retrieve library notifications from gmail
I followed the gmailr set up instructions to authenticate myself and enable R’s gmailr package to interact with the Gmail API for my personal Gmail account, which was fairly straightforward. This required some point and click in other interfaces, followed by two lines of R code.
gm_auth_configure(path = "path/credentials.json")
gm_auth()Once authenticated, I retrieved the email notifications from my gmail account. It was not immediately clear to me how to do this, but this stack overflow thread helped.
# 1 - retrieve messages corresponding to this search ----
messages <- gmailr::gm_messages("Bucks County Library System - Available Hold Pickup Notice")
# 2 - extract ids from messages corresponding to search ----
message_ids <- gmailr::gm_id(messages)
# 3 - extract contents from messages with these ids -----
message_full <- purrr::map(message_ids, gmailr::gm_message)
# 4 - extract message body from contents -----
message_body <- purrr::map(message_full, gmailr::gm_body)This resulted in 67 email notifications from June 22, 2020 to December 30, 3020, containing from 1 to 11 books per email. Here is an example character string returned to me, corresponding to the email notification shown above.
message_body[[66]]
[1] "Wednesday, June 24, 2020\r\n\r\nBCFL Doylestown Branch\r\n150 South Pine Street\r\nDoylestown, PA\r\n18901-4932\r\n215-348-9081\r\n\r\n Shannon M Pileggi\r\n \r\n Doylestown, PA\r\n 18901\r\n \r\n\r\nDear Shannon Pileggi,\r\n \"AVAILABLE HOLD PICKUP NOTICE\"\r\n\r\nGood news! The material you requested is available for pickup from the library \r\nfor 2 weeks from the date of this email.\r\n\r\nPlease call your library to learn about curbside pickup or visit buckslib.org/cu\r\nrbside to see instructions for curbside pickup at your library.\r\n\r\nWe are accepting returns at our bookdrops.\r\n\r\nIf you no longer need this material, please cancel your hold by calling your \r\nlibrary or updating the information in the Review My Account section of My \r\nAccount: buckslib.org/MyAccount \r\n\r\nThank you.\r\n\r\n*********\r\nPlease do not respond to this email; it has been sent automatically from an \r\nunmonitored mailbox. For questions, contact the library listed above.\r\n\r\n 1 My trip to the science museum / by Mercer Mayer.\r\n Mayer, Mercer, 1943-\r\n call number:E FICTION MAYER copy:1 \r\n Pickup by:7/8/2020 \r\n hold pickup library:BCFL Doylestown Branch \r\n \r\n \r\n\r\n 2 American girl. Bitty Baby has a tea party / by Kirby Larson & Sue\r\n Cornelison.\r\n Larson, Kirby\r\n call number:E FICTION AMERICAN copy:3 \r\n Pickup by:7/8/2020 \r\n hold pickup library:BCFL Doylestown Branch \r\n \r\n \r\n\r\n 3 The day the crayons quit / by Drew Daywalt ; pictures by Oliver Jeffers.\r\n Daywalt, Drew.\r\n call number:E FICTION DAYWALT copy:1 \r\n Pickup by:7/8/2020 \r\n hold pickup library:BCFL Doylestown Branch \r\n \r\n \r\n\r\n"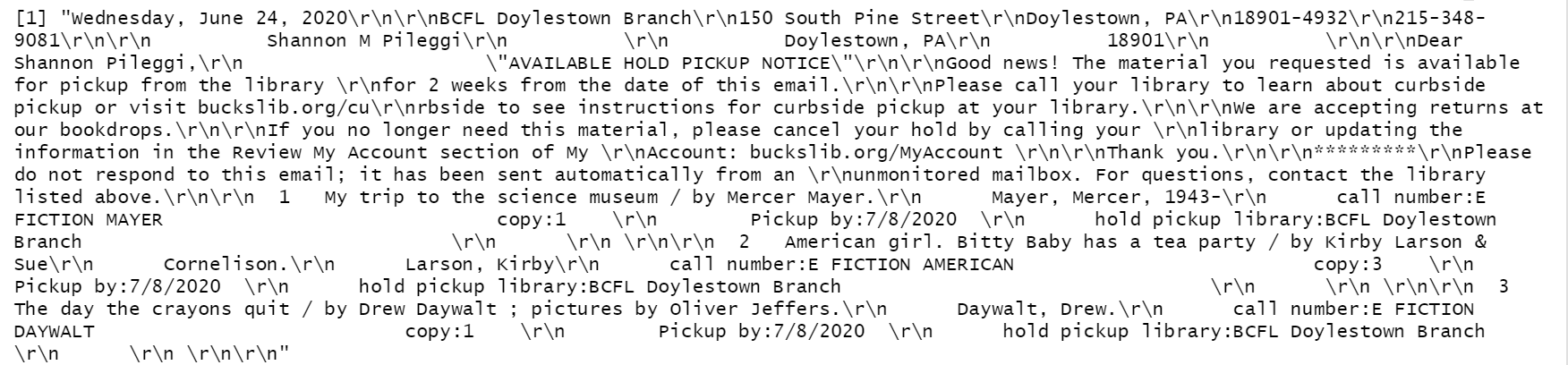
2 {stringr} extract title and author from email
I then did my best to convert the date of the email notification, the book title, and book author to a tibble. This was a three step iterative process.
First, I created a list with the dates of the 67 emails.
# 1 - extract date of email notification ----
message_date <- purrr::map(
message_body,
# start string at first character, end where 2020 ends ----
~ stringr::str_sub(.x , start = 1, end = str_locate(.x, "2020") %>% .[2]) %>%
# convert text string to date ----
lubridate::mdy(.)
)
# view date corresponding to email notice ----
message_date[[66]]
[1] "2020-06-24"Second, I did some initial cleaning to remove the introductory text, and then split the strings by numbers.
message_books <- purrr::map(
message_body,
# remove formatting text, affect other stringr code ----
~ str_remove_all(.x, "[\\r|\\n]") %>%
# remove all introductory text ----
str_remove(".* listed above. ") %>%
# split string when any number is identified ----
str_split("[[:digit:]] ")
)
# view entries corresponding to email notice ----
message_books[[66]]
[[1]]
[1] ""
[2] "My trip to the science museum / by Mercer Mayer. Mayer, Mercer, 1943- call number:E FICTION MAYER copy:"
[3] " Pickup by:7/8/202"
[4] " hold pickup library:BCFL Doylestown Branch "
[5] "American girl. Bitty Baby has a tea party / by Kirby Larson & Sue Cornelison. Larson, Kirby call number:E FICTION AMERICAN copy:"
[6] " Pickup by:7/8/202"
[7] " hold pickup library:BCFL Doylestown Branch "
[8] "The day the crayons quit / by Drew Daywalt ; pictures by Oliver Jeffers. Daywalt, Drew. call number:E FICTION DAYWALT copy:"
[9] " Pickup by:7/8/202"
[10] " hold pickup library:BCFL Doylestown Branch " Third, I converted this to a tibble, removed all non-book rows, and iterated with stringr functions to get the title and author as best as I could. This was challenging as not all entries had consistent formatting, and some adjustments I could make here improved the Google Books API search later. Some of the stringr functions could probably be collapsed, but the code mimics the steps I took and also allowed me to easily backtrack on failed attempts.
# split author and books into separate variables ----
books <- message_books %>%
# coerce list to tibble ----
tibble() %>%
# rename first column ----
rename("text" = 1) %>%
# unnest list text field ----
unnest(cols = "text") %>%
# merge in notice date ----
mutate(notice_date = message_date %>% unlist() %>% as_date()) %>%
# unnest one more time ----
unnest(cols = "text") %>%
# remove strings starting with spaces, these are not books ----
filter(!str_sub(text, 1, 1) %in% c(" ", "")) %>%
# a lot of iteration here to extract author/title ----
# sort by notice date before assigning id ----
arrange(notice_date) %>%
mutate(
# create id ----
id = row_number(),
# clean title until looks ok ----
title = str_remove(text, " /.*") %>%
str_remove("Wells.*") %>%
str_remove(" \\[.*") %>%
str_remove(": from.*") %>%
str_remove("\\*") %>%
str_remove("Nino") %>% # affected api search ----
str_remove("American [Gg]irl.") %>% # affected api search ----
str_trim(),
# clean author until looks ok ----
author = str_remove(text, ".* /") %>%
str_remove("Sendak, Maurice") %>%
str_remove(" ; .*") %>%
str_remove("\\[") %>%
str_remove("\\]") %>%
str_remove(".* by ") %>%
str_remove(".*! ") %>%
str_remove("and .*") %>%
# remove everything after a period, but affected authors with first or middle initial ----
str_remove("\\..*") %>%
str_remove("\\*") %>%
str_remove_all("& Sue .*| an |book") %>%
str_squish()
) %>%
# remove non pre-k books (I mostly read on kindle) ----
dplyr::filter(!(title %in% c("Pax", "Luster", "Last night in Montreal : a novel"))) %>%
# count number of books per emails ----
group_by(notice_date) %>%
add_count() %>%
ungroup()
# view entries corresponding to email notice ----
books %>%
filter(notice_date == "2020-06-24") %>%
dplyr::select(text, title, author) %>%
knitr::kable()| text | title | author |
|---|---|---|
| My trip to the science museum / by Mercer Mayer. Mayer, Mercer, 1943- call number:E FICTION MAYER copy: | My trip to the science museum | Mercer Mayer |
| American girl. Bitty Baby has a tea party / by Kirby Larson & Sue Cornelison. Larson, Kirby call number:E FICTION AMERICAN copy: | Bitty Baby has a tea party | Kirby Larson |
| The day the crayons quit / by Drew Daywalt ; pictures by Oliver Jeffers. Daywalt, Drew. call number:E FICTION DAYWALT copy: | The day the crayons quit | Drew Daywalt |
3 {httr} query google books api
I then got started with the Google Books API. Some key steps in this process included:
Exploring Google Books and doing some manual searches to get a feel for how it behaves and what it returns.
Identifying the format to get started with the API:
https://www.googleapis.com/books/v1/{collectionName}/resourceID?parameters.Understanding the search terms permissible in the query (like
inauthorandintitle):https://www.googleapis.com/books/v1/volumes?q=search+terms.Obtaining an API key (google console developer -> enable google books api -> create credentials -> calling API from other non UI -> get API key). However, this ended up being unnecessary for the search I executed.
Then I used the httr package to actually perform the query. First, I defined the url.
# url base format ----
url <- "https://www.googleapis.com/books/v1/volumes"Next I created a wrapper function around httr::GET to allow for a search by title and author, or title alone.
get_book <- function(this_title, this_author = NA){
httr::GET(
url = url,
query = list(
key = token,
q = ifelse(
is.na(this_author),
glue::glue('intitle:{this_title}'),
glue::glue('intitle:{this_title}+inauthor:{this_author}')
)))
}I then performed an initial search with title and author. I learned that the API would error out with too many queries in quick succession, and I included Sys.sleep to slow down the search.
# first search with title and author ----
# create progress bar for mapping ----
p <- dplyr::progress_estimated(nrow(books))
books_1 <- books %>%
mutate(book_info = purrr::map2(title, author,
function(x, y) {
# print progress bar ----
p$tick()$print()
# add in delay for api ----
Sys.sleep(1)
get_book(x, y)
}))From there, I checked the status code, extracted book content, and checked to see if any items were empty (which meant that no result was returned). In addition, more than one search result could have been returned; only the first was extracted.
books_1_content <- books_1 %>%
mutate(
# extract status code: 200 = success ----
status_code = purrr::map_int(book_info, "status_code"),
# extract relevant content from author title search ----
book_items = purrr::map(book_info, ~ httr::content(.x)[["items"]][[1]][["volumeInfo"]]),
# check to see if items are empty ----
empty_items = purrr::map_lgl(book_items, rlang::is_empty)
)The initial title and author search were all technically successful, though 10 searches results in empty items.
books_1_content %>% count(status_code, empty_items)
# A tibble: 2 x 3
status_code empty_items n
<int> <lgl> <int>
1 200 FALSE 204
2 200 TRUE 10For these 10 items, I manually checked some with various searches on Google Books, and I noticed that some actually did have an entry, but did not have an author in that entry, so I repeated the search but with title only.
# 10 books did not have a result with author title search ----
p <- dplyr::progress_estimated(nrow(books))
# perform title search only ----
books_2 <- books_1_content %>%
# keep only empty items for another search ----
filter(empty_items == TRUE) %>%
# keep original first six columns ----
select(1:6) %>%
mutate(book_info = purrr::map(title,
function(x) {
p$tick()$print()
Sys.sleep(1)
get_book(x)
}))
books_2_content <- books_2 %>%
mutate(
# extract status code: 200 = success ----
status_code = purrr::map_int(book_info, "status_code"),
# extract relevant content from author only search ----
book_items = purrr::map(book_info, ~ httr::content(.x)[["items"]][[1]][["volumeInfo"]]
),
# check to see if items are empty ----
empty_items = purrr::map_lgl(book_items, rlang::is_empty)
)These 10 items were all technically successful and contained result contents.
books_2_content %>% count(status_code, empty_items)
# A tibble: 1 x 3
status_code empty_items n
<int> <lgl> <int>
1 200 FALSE 10In these two searches, I created a nested tibble with two nested lists:
book_infois a very long list which contains the full result from the original query.
# showing entry for a book in initial email notification ----
books_1_content[["book_info"]][[2]]
Response [https://www.googleapis.com/books/v1/volumes?key=AIzaSyCUqoG382nRpWFTT-3BKX-m_cB7UyfVTMw&q=intitle%3AMy%20trip%20to%20the%20science%20museum%2Binauthor%3AMercer%20Mayer]
Date: 2021-01-03 16:42
Status: 200
Content-Type: application/json; charset=UTF-8
Size: 6.14 kB
{
"kind": "books#volumes",
"totalItems": 2,
"items": [
{
"kind": "books#volume",
"id": "htdVvgAACAAJ",
"etag": "zxSYXCOb+ho",
"selfLink": "https://www.googleapis.com/books/v1/volumes/htdV...
"volumeInfo": {
...book_itemscontains into the specific bits of information I considered for extraction to augment book information.
# showing entry for a book in initial email notification ----
str(books_1_content[["book_items"]][[2]])
List of 19
$ title : chr "My Trip to the Science Museum"
$ authors :List of 1
..$ : chr "Mercer Mayer"
$ publisher : chr "Little Critter"
$ publishedDate : chr "2017-03-07"
$ description : chr "For use in schools and libraries only. It's Science Day and Little Critter and his classmates are heading to th"| __truncated__
$ industryIdentifiers:List of 2
..$ :List of 2
.. ..$ type : chr "ISBN_10"
.. ..$ identifier: chr "060639625X"
..$ :List of 2
.. ..$ type : chr "ISBN_13"
.. ..$ identifier: chr "9780606396257"
$ readingModes :List of 2
..$ text : logi FALSE
..$ image: logi FALSE
$ pageCount : int 24
$ printType : chr "BOOK"
$ categories :List of 1
..$ : chr "Juvenile Fiction"
$ maturityRating : chr "NOT_MATURE"
$ allowAnonLogging : logi FALSE
$ contentVersion : chr "preview-1.0.0"
$ panelizationSummary:List of 2
..$ containsEpubBubbles : logi FALSE
..$ containsImageBubbles: logi FALSE
$ imageLinks :List of 2
..$ smallThumbnail: chr "http://books.google.com/books/content?id=htdVvgAACAAJ&printsec=frontcover&img=1&zoom=5&source=gbs_api"
..$ thumbnail : chr "http://books.google.com/books/content?id=htdVvgAACAAJ&printsec=frontcover&img=1&zoom=1&source=gbs_api"
$ language : chr "en"
$ previewLink : chr "http://books.google.com/books?id=htdVvgAACAAJ&dq=intitle:My+trip+to+the+science+museum%2Binauthor:Mercer+Mayer&"| __truncated__
$ infoLink : chr "http://books.google.com/books?id=htdVvgAACAAJ&dq=intitle:My+trip+to+the+science+museum%2Binauthor:Mercer+Mayer&"| __truncated__
$ canonicalVolumeLink: chr "https://books.google.com/books/about/My_Trip_to_the_Science_Museum.html?hl=&id=htdVvgAACAAJ"4 {purrrr} extract content from search results
To assemble the final data, I combined the results of the two searches and proceeded to extract information from book_info. A tricky part here was that not all API results returned the same information, and if the named item did not exist the entire mapping would fail. My solution was to check if the named element existed for extraction, and otherwise return NA. I also checked to see if there was a fuzzy match between the author I originally extracted from the emails versus the author that the Google Books API returned.
books_all <- books_1_content %>%
# keep non-empty items from title author search ----
filter(empty_items == FALSE) %>%
# append results from title only search ---
bind_rows(books_2_content) %>%
# remove original api results ----
dplyr::select(-book_info) %>%
mutate(
# extract fields from api results ----
book_title = purrr::map_chr(book_items, ~ ifelse(
rlang::has_name(.x, "title"), .x[["title"]], NA
)),
book_author = purrr::map_chr(book_items, ~ ifelse(
rlang::has_name(.x, "authors"), str_c(unlist(.x[["authors"]]), collapse = ", "),
NA
)),
book_publish_date = purrr::map_chr(book_items, ~ ifelse(
rlang::has_name(.x, "publishedDate"), .x[["publishedDate"]], NA
)),
book_volume_link = purrr::map_chr(book_items, ~ ifelse(
rlang::has_name(.x, "canonicalVolumeLink"), .x[["canonicalVolumeLink"]], NA
)),
book_image_link = purrr::map_chr(book_items, ~ ifelse(
rlang::has_name(.x, "imageLinks"), .x[["imageLinks"]][["smallThumbnail"]], NA
)),
# clean book publish date to year only ----
book_publish_year = str_sub(book_publish_date, start = 1, end = 4) %>% as.numeric(),
# check for fuzzy matching of author from email vs api result ----
author_fuzzy = purrr::map2(author, book_author, agrep),
# if result is 1, there is a fuzzy match; otherwise, not ----
author_match = purrr::map_lgl(author_fuzzy, ~ length(.x) > 0)
)If the authors matched, I assumed a matching result was returned. For the 13 authors that did not match, I manually inspected entries for further cleaning.
books_all %>%
filter(author_match == FALSE) %>%
# title, author from email; book_title, book_author from api ---
select(id, title, author, book_title, book_author) %>%
knitr::kable()| id | title | author | book_title | book_author |
|---|---|---|---|---|
| 58 | Snow sisters! | Kerri Kokias, Teagan White | Snow Sisters! | Kerri Kokias |
| 75 | Square | Mac Barnett & Jon Klassen | Square | Mac Barnett |
| 109 | Spend it! : a moneybunny book | Cinders McLeod | Spend It! | NA |
| 179 | Back to school with the Berenstain Bears | Stan & Jan Berenstain | Back to School with the Berenstain Bears | Stan Berenstain, Jan Berenstain |
| 15 | Splat the Cat and the quick chicks | Laura Driscoll | Splat the Cat and the Quick Chicks | Rob Scotton |
| 28 | Raindrop, plop! | Wendy Cheyette Lewison | Plop the Raindrop | Kevin Alan Richards |
| 54 | Drawn together | Minh Le | Drawn Together | Leah Pearlman |
| 89 | All the world | Marla Frazee | All the World Loves a Quarrel | Daniel Wright Kittredge |
| 139 | Chee-Kee : a panda in Bearland | Sujean Rim | Chee-Kee: A Panda in Bearland | NA |
| 140 | Birdie’s happiest Halloween | Sujean Rim | Birdie’s Happiest Halloween | NA |
| 159 | Costume fun! | Wells, Rosemary | Creative Homemade Halloween Costume Ideas - Fun, Unusual and Inexpensive | M Osterhoudt |
| 203 | Corduroy’s Christmas surprise | Lisa McCue | Corduroy’s Christmas Surprise | Don Freeman |
| 211 | Rudolph the Red-Nosed Reindeer | Alan Benjamin | Rudolph the Red-Nosed Reindeer | Robert L. May |
Of these 13 books, I determined that there were:
3 instances where Google Books had missing author but the search result was a correct match
5 instances where the authors did not fuzzy match, but the search result was a correct match
5 instances with an incorrect match
I finished cleaning the books data with this in mind, and also formatted fields to show the thumbnail images and convert titles to links.
books_clean <- books_all %>%
#filter(author_match == TRUE) %>%
mutate(
# replace author as extracted from email ----
book_author = ifelse(is.na(book_author), author, book_author),
# replace author as extracted from email ----
book_author = case_when(
# correct result not available from api search ----
title %in% c("Raindrop, plop!", "Drawn together", "All the world", "Costume fun!", "Rudolph the Red-Nosed Reindeer") ~ author,
TRUE ~ book_author
),
# replace title as extracted from email ----
book_title = case_when(
# correct result not available on google books ----
title %in% c("Raindrop, plop!", "Drawn together", "All the world", "Costume fun!", "Rudolph the Red-Nosed Reindeer") ~ title,
TRUE ~ book_title
),
# make volume link missing ----
book_volume_link = case_when(
# correct result not available on google books ----
title %in% c("Raindrop, plop!", "Drawn together", "All the world", "Costume fun!", "Rudolph the Red-Nosed Reindeer") ~ NA_character_,
TRUE ~ book_volume_link
),
# make image link missing ----
book_image_link = case_when(
# correct result not available on google books ----
title %in% c("Raindrop, plop!", "Drawn together", "All the world", "Costume fun!", "Rudolph the Red-Nosed Reindeer") ~ NA_character_,
TRUE ~ book_image_link
),
# make year missing ----
book_publish_year = case_when(
title %in% c("Raindrop, plop!", "Drawn together", "All the world", "Costume fun!", "Rudolph the Red-Nosed Reindeer") ~ NA_real_,
TRUE ~ book_publish_year
),
# create html text strings for display in table ----
image_link_html = gt::web_image(url = book_image_link, height = 80),
title_link_html = ifelse(
is.na(book_volume_link),
# if link unavailable, print title with no link ----
book_title,
str_c("<a href='", book_volume_link, "' target='_blank'>", book_title, "</a>")
)
) %>%
arrange(id) %>%
# rename for table ---
dplyr::select(
ID = id,
Preview = image_link_html,
Title = title_link_html,
`Author(s)` = book_author,
`Published` = book_publish_year,
`Notification` = notice_date
) 5 {DT} present books in an interactive table
Finally! Over the last 6 months, we read 214 amazing books. If you aren’t familiar with this type of table (I’m looking at you, Mom), note that this table is interactive. You can search for any word like “Carle” or “bear” in the search bar, change the number of entries shown, and sort by published date (for example) by using the light gray triangles in the header of the table.
books_clean %>%
DT::datatable(
escape = FALSE,
rownames = FALSE,
options = list(
columnDefs = list(
list(className = 'dt-center', targets = c(1, 4, 5)),
list(className = 'dt-left', targets = c(2:3))
),
pageLength = 15,
lengthMenu = seq(15, 225, by = 15)
)
)Technical reflection
This project was certainly a learning experience! I used the gmailr and httr packages for the first time, in addition to accessing my first API. Here are some of the challenges I faced:
My emails from the library did not always have consistent punctuation in reporting available books.
Book titles are not consistently presented; e.g.,
Up up up downin my email from the library vsUp, Up, Up, Down!in the Google Books result.Author names can be formatted differently across books (books with multiple authors or authors who identify with a middle initial, and period, in their name).
Authorship is not always consistently defined. For example,
I Can Read! Splat the Cat and the Quick Chickswas attributed to Laura Driscoll according to the library (who actually wrote the text), but Rob Scotton according to Google Books (who wrote the original Splat the Cat books that this was based on).The API results varied in information presented; for example, not all results contained authors or preview images.
Performing the API search in two phases (author and title vs title only) gave eight additional correct results and five additional incorrect results. I’m not sure if that is worth it considering the manual effort to identify the incorrect results.
The books shown in my search are not necessarily the exact books that I read. For example, I did not read the 2021 edition of “What the Ladybird Heard” as shown in my final table, which would not have been available when I read it in October 2020.
I encountered more issues with
NULL,integer(0), and empty items than ever before (which is not the same asNA🤣).
Alternative solutions to these challenges are welcome! You can download books.rda (which contains message_body, books_1, and books_2) from my github repo.
Personal note
Like many aspects of life, COVID-19 changed our relationship with the library. Previously, our family library experience consisted of leisurely browsing for a couple of books followed by a quick exit when the girls inevitably started playing hide and seek in the aisles. Instead, I now actively research children’s books to check out. Without this change, I may have not have encountered many books that we now treasure. Completion of this cataloging project with preview images allows us to better recall the books we read together, and decide together which books we want to read again in the future. I hope that nurturing a love for books and reading can help to alleviate the lapse in formal pre-k education my children experienced this year.
Acknowledgements
Anthony Pileggi (my husband) talked me through my first API and discussed possible solutions to some coding challenges. Anthony is a data scientist currently specializing in e-commerce for outdoor power equipment at Paul B. Moyer and Sons, and sometimes he makes fun R packages like this.