
Figure 1: Artwork adapted from @allison_horst.
Last updated
This post was last updated on 2021-09-14 to reflect package updates.
TL; DR
The haven, labelled, and sjlabelled packages can be used to effectively work with SPSS, SAS, and Stata data sets in R through implementation of the haven_labelled class, which stores variable and value labels. Here are my most used functions for getting started with labelled data:
| Purpose | Function |
|---|---|
| 1. Import SPSS labelled data | haven::read_sav() |
| 2. Create data dictionary | labelled::generate_dictionary() |
3. Identify if variable is haven_labelled |
haven::is.labelled() |
4. Convert haven_labelled variables to numeric |
base::as.numeric() |
5. Convert haven_labelled variables to factors |
haven::as_factor() |
| 6. Convert variable label to variable name | sjlabelled::label_to_colnames() |
Introduction
Labelled data traditionally, though not exclusively, arises in survey data. SAS, SPSS, and Stata have established infrastructures for labelled data, which consists of metadata in the form of variable and value labels. This post is for R users who already have a SPSS (.sav), SAS (.sas7bdat), or Stata (.dta) data file and want to incorporate the labelled data features into their R workflow. With R’s haven, labelled, and sjlabelled packages, you can leverage the inherent data labelling structure in these data sets to work interactively with variable and value labels, making it easier to navigate data while also allowing the user to convert metadata to data. This post discusses general characteristics of labelled data and practical tips for data analysis with labelled data.
YRBSS labelled data
The Youth Risk Behavior Surveillance System (YRBSS) is a publicly available data set from the Centers for Disease Control and Prevention (CDC) that “monitors health-related behaviors that contribute to the leading causes of death and disability among youth and adults.” On Aug 9, 2020, I downloaded YRBSS materials from the CDC website. This site has both the the 2017 national data (sadc_2017_national.dat) and the SPSS syntax to convert the .dat file to an SPSS labelled data file (2017_sadc_spss_input_program.sps). I do have an SPSS license, and I used the SPSS syntax to convert the .dat file to an SPSS labelled data file (sadc_2017_national.sav). As the .sav data file is not available on the CDC site, you can download the .sav data from my github repo.
Getting started
This material was developed using:
| Software / package | Version |
|---|---|
| R | 4.0.5 |
| RStudio | 1.4.1103 |
tidyverse |
1.3.1 |
here |
0.1 |
haven |
2.3.1 |
labelled |
2.8.0 |
sjlabelled |
1.1.7 |
Importing labelled data
I use the haven package to import SPSS (.sav) data files.
Variables in a data set have a class, which consists of assignments like numeric, character, and factor, among others. When labelled features are present, the haven package assigns a class of haven_labelled. This is important to know as many packages you work with may not have methods for haven_labelled objects.
When I first started working with SPSS data files, I also explored the foreign package, which preceeds haven. Using foreign takes a bit longer than haven, can result in truncation of long character variables, and produces a different labelled data structure compared to haven. I have a strong preference for the haven package.
Creating a data dictionary
A data dictionary contains metadata about your data. The labelled::generate_dictionary function can be used to create a data dictionary, extracted straight from your data. The usefulness of the data dictionary depends on the quality of your metadata.
# create data dictionary ----
dictionary <- labelled::generate_dictionary(dat_raw)
The result is a data frame in my R environment with the number of observations equal to number of variables in the original data set. I can interactively explore the dictionary in R to quickly find variables or documentation of interest. For example, I can find all variables related to “weapons” with a search.
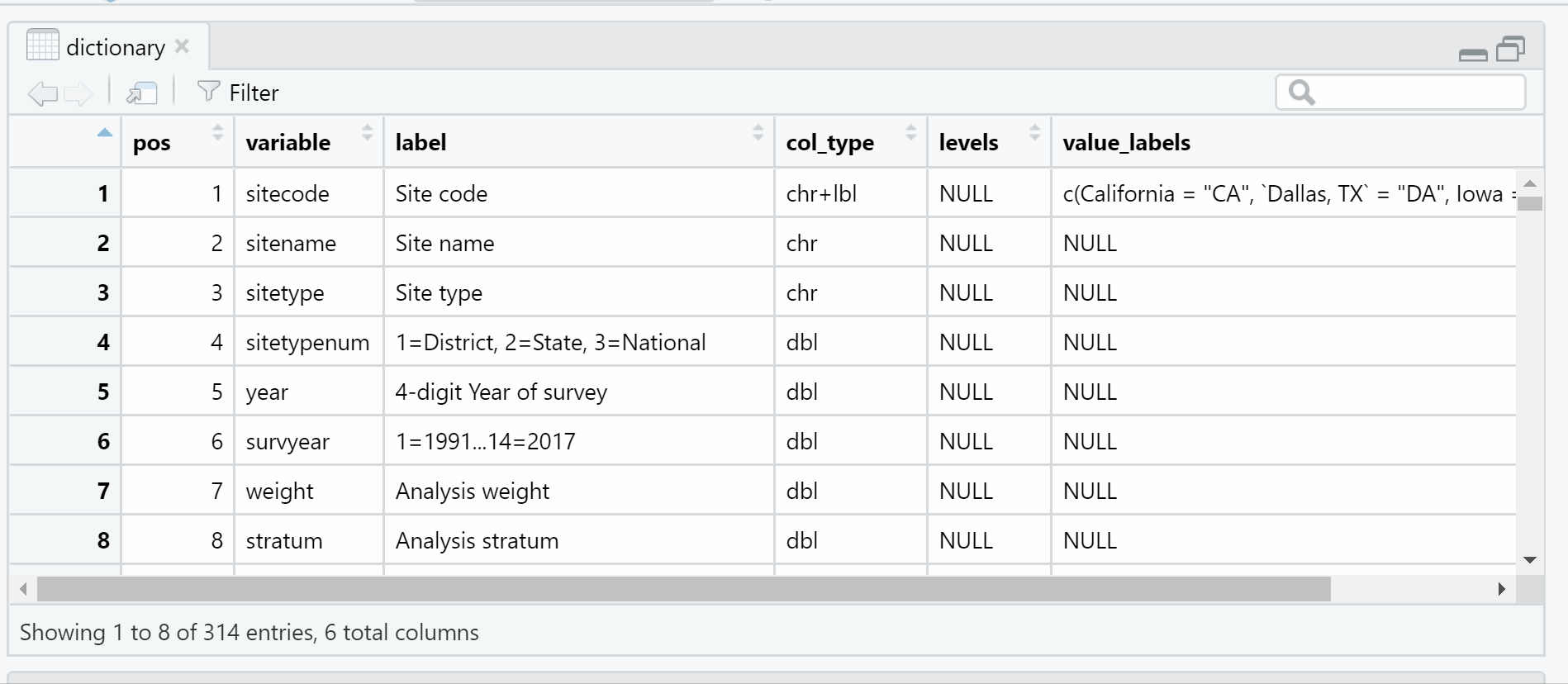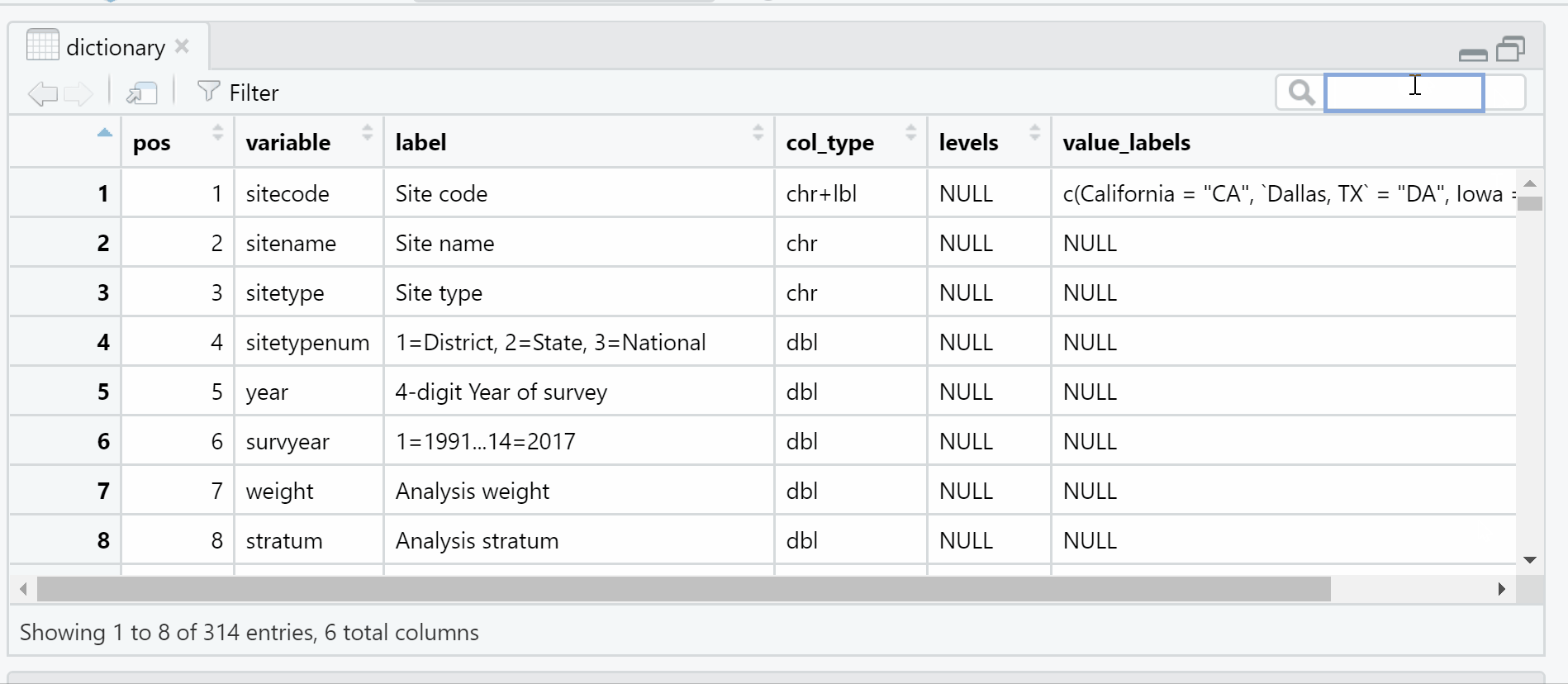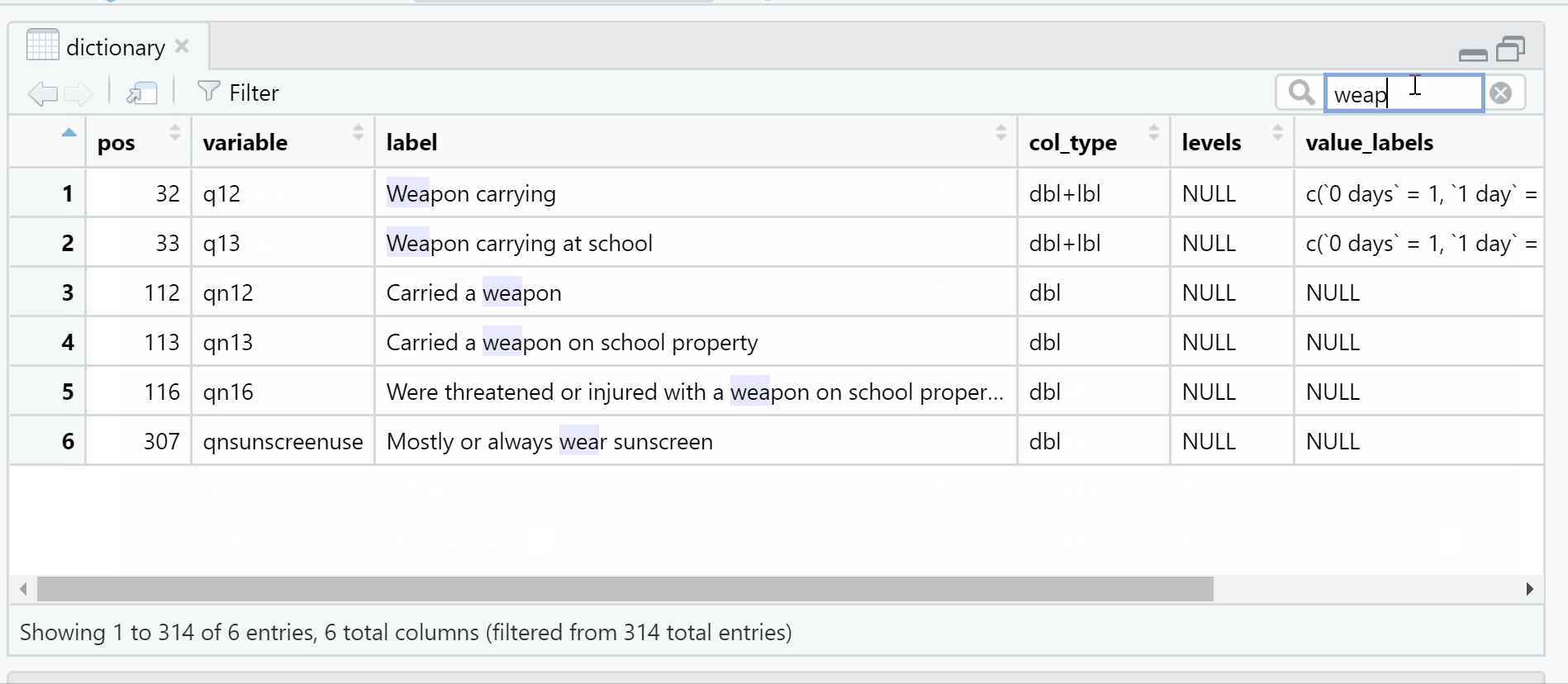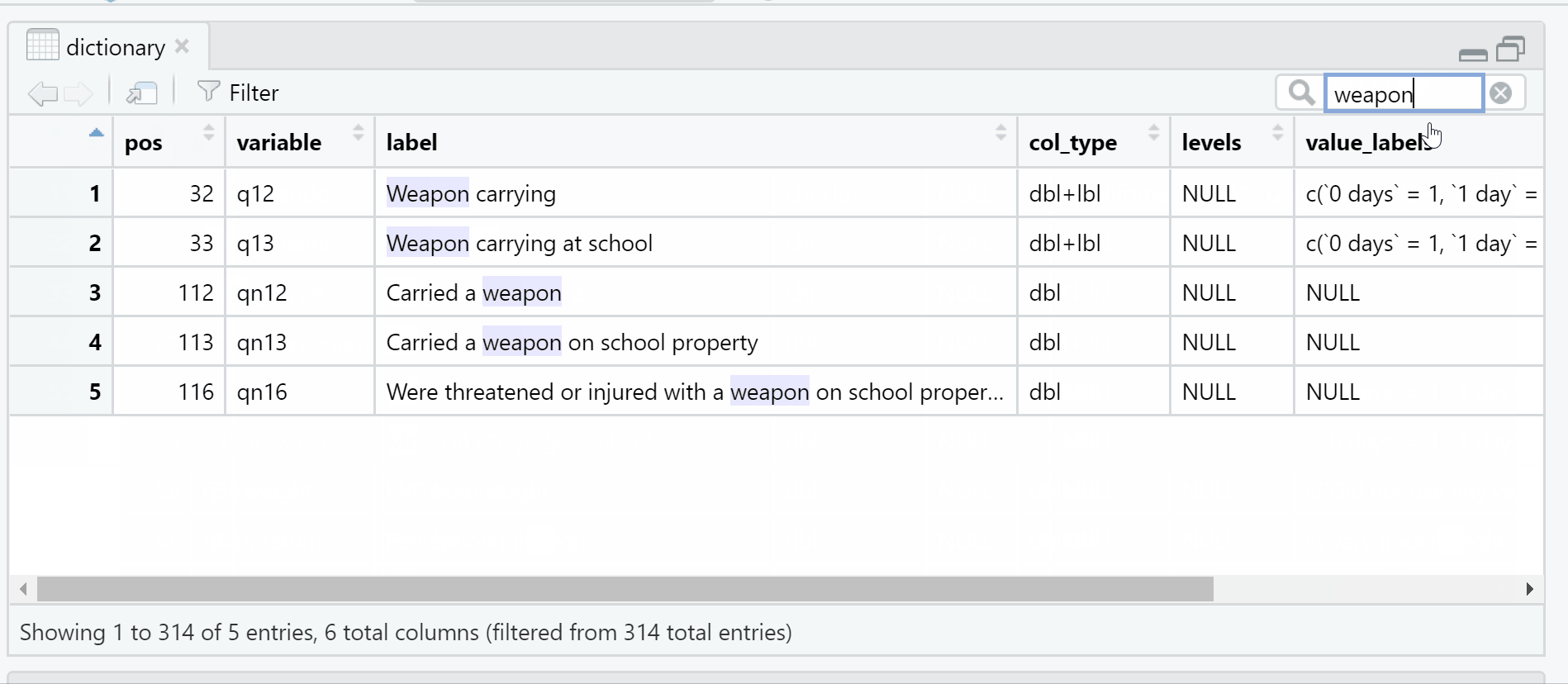
Figure 2: Gif demonstrating search feature in data viewer utilized to find variables with the word weapon in the data dictionary.
Identifying labelled features
Standard data consists of variables (e.g., country) and values (e.g. US, UK, CA). When working with labelled data, variables and values each have two features. Variables consist of a name and a label; values consist of a code and a label. For example, here are the features of the q8 variable.
| Feature | Assignment |
|---|---|
| Variable name | q8 |
| Variable label | Seat belt use |
| Value codes | 1, 2, 3, 4, 5 |
| Value labels | Never, Rarely, Sometimes, Most of the time, Always |
You can see this information in the data dictionary - here is a snippet of the dictionary for three variables. The value_labels field combines the value codes and value labels.
dictionary %>%
dplyr::filter(variable %in% c("q8", "q11", "q12")) %>%
dplyr::select(variable, label, value_labels)
variable label
q8 Seat belt use
q11 Texting and driving
q12 Weapon carrying
value_labels
[1] Never; [2] Rarely; [3] Sometimes; [4] Most of the time; [5] Always
[1] Did not drive; [2] 0 days; [3] 1 or 2 days; [4] 3 to 5 days; [5] 6 to 9 days; [6] 10 to 19 days; [7] 20 to 29 days; [8] All 30 days
[1] 0 days; [2] 1 day; [3] 2 or 3 days; [4] 4 or 5 days; [5] 6 or more days To dive a bit deeper, you can see the class of the q8 variable:
and how the metadata of q8 is stored.
tibble [203,663 x 1] (S3: tbl_df/tbl/data.frame)
$ q8: dbl+lbl [1:203663] 2, NA, 4, 4, 1, 1, 3, 5, 4, 4, ...
..@ label : chr "Seat belt use"
..@ format.spss : chr "F1.0"
..@ display_width: int 4
..@ labels : Named num [1:5] 1 2 3 4 5
.. ..- attr(*, "names")= chr [1:5] "Never" "Rarely" "Sometimes" "Most of the time" ...You don’t need to get into the weeds of this to work effectively with labelled data, but knowing this can help troubleshoot errors.
Viewing labelled features
Beyond the dictionary, labelled features can also be seen when working with your data interactively. The console simultaneously prints value codes and labels side by side, with the code first followed by the label in brackets.
dat_raw %>%
dplyr::select(q8, q11, q12)
# A tibble: 203,663 x 3
q8 q11 q12
<dbl+lbl> <dbl+lbl> <dbl+lbl>
1 2 [Rarely] NA 4 [4 or 5 days]
2 NA NA NA
3 4 [Most of the time] NA 3 [2 or 3 days]
4 4 [Most of the time] NA 5 [6 or more days]
5 1 [Never] NA 5 [6 or more days]
6 1 [Never] NA 1 [0 days]
7 3 [Sometimes] NA 2 [1 day]
8 5 [Always] NA 1 [0 days]
9 4 [Most of the time] NA 5 [6 or more days]
10 4 [Most of the time] NA NA
# ... with 203,653 more rowsSometimes the alignment throws me a bit when I am reading this as the value codes and labels are left aligned, which places the value codes associated with q12 closer to q11.
When viewing the data frame in RStudio, the data frame displays the variable label under the variable name; however, only value codes (and not value labels) are displayed.

Figure 3: Screenshot showing how haven labelled data appear in the viewer pane, with variable labels under the variable name, and value codes (not value labels) displayed.
Common operations
I primarily use three packages for working with labelled data: haven, labelled, and sjlabelled. These three packages do have some overlap in functionality, in addition to naming schemes that differ but achieve the same objective (e.g., haven::as_factor vs sjlabelled::as_label), or naming schemes that are the same but achieve different objectives (e.g., haven::as_factor vs sjlabelled::as_factor). 😬 To compound confusion, the concept of a label can refer to either variable or value labels. Frequently, plural function names refer to value labels, as in haven::zap_labels or labelled::remove_val_labels.
Here are operations I commonly perform on labelled data:
Evaluate if variable is of class
haven_labelled.Why? Troubleshooting, exploring, mutating.
Function(s):
haven::is.labelled()
Convert
haven_labelledvariable tonumericvalue codes.Why? To treat the variable as continuous for analysis. For example, if a 1-7 rating scale imports as labelled and you want to compute a mean.
Function(s):
base::as.numeric()(strips variable of all metadata),haven::zap_labels()andlabelled::remove_val_labels(removes value labels, retains other metadata)
Convert
haven_labelled()variable tofactorwith value labels.Why? To treat the variable as categorical for analysis.
Function(s):
haven::as_factor(),labelled::to_factor(),sjlabelled::as_label(). As far as I can tell, these three functions have the same result. By default, the factor levels are ordered by value codes.
Convert variable label to variable name.
Why? For more informative or readable variable names.
Function(s):
sjlabelled::label_to_colnames()
Example
For this example, I reduce the data set to 2017 records only and select three variables related to carrying weapons and safety, all of which are measured on the same scale.
# preview data ----
dat_2017
# A tibble: 14,765 x 4
record q12 q13 q15
<dbl> <dbl+lbl> <dbl+lbl> <dbl+lbl>
1 1509749 5 [6 or more days] 1 [0 days] 1 [0 days]
2 1509750 1 [0 days] 1 [0 days] 1 [0 days]
3 1509751 1 [0 days] 1 [0 days] 3 [2 or 3 days]
4 1509752 1 [0 days] 1 [0 days] 1 [0 days]
5 1509753 1 [0 days] 1 [0 days] 1 [0 days]
6 1509754 1 [0 days] 1 [0 days] 2 [1 day]
7 1509755 5 [6 or more days] 1 [0 days] 5 [6 or more days]
8 1509756 1 [0 days] 1 [0 days] 1 [0 days]
9 1509757 1 [0 days] 1 [0 days] 1 [0 days]
10 1509758 1 [0 days] 1 [0 days] 1 [0 days]
# ... with 14,755 more rowsThis code produces a bar plot showing the frequencies of the three variables from data as imported, displaying variable names and value codes.
# bar plot 1 ----
dat_2017 %>%
pivot_longer(
cols = -1,
names_to = "variable",
values_to = "days"
) %>%
count(variable, days) %>%
# include factor(days) to correctly show value codes in ggplot ----
ggplot(aes(x = n, y = factor(days))) +
facet_wrap(. ~ variable) +
geom_col()
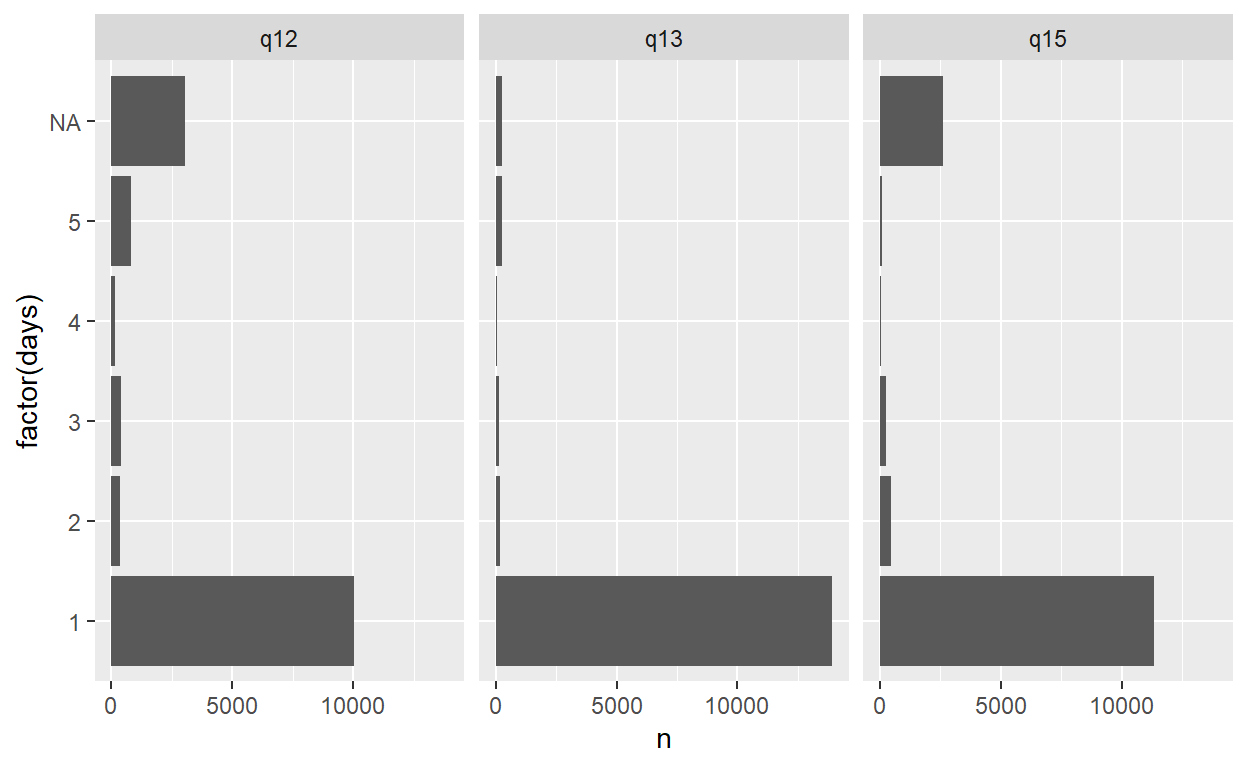
Figure 4: Bar plot 1 displays variable names and value codes
Now I add two lines of code to implement two changes - convert the variables to factors and convert the variable labels to variable names. This plot displays variable labels and value labels, producing a more informative figure.
# bar plot 2 ----
dat_2017 %>%
# --------------------------------------------------------------
# change 1: convert haven_labelled variables to factors ----
mutate_if(haven::is.labelled, haven::as_factor) %>%
# change 2: convert variable labels to variable names ----
sjlabelled::label_to_colnames() %>%
# --------------------------------------------------------------
pivot_longer(
cols = -1,
names_to = "variable",
values_to = "days"
) %>%
count(variable, days) %>%
# unnecessary to include factor(days) here as was already converted in change 1 ----
ggplot(aes(x = n, y = days)) +
facet_wrap(. ~ variable) +
geom_col()
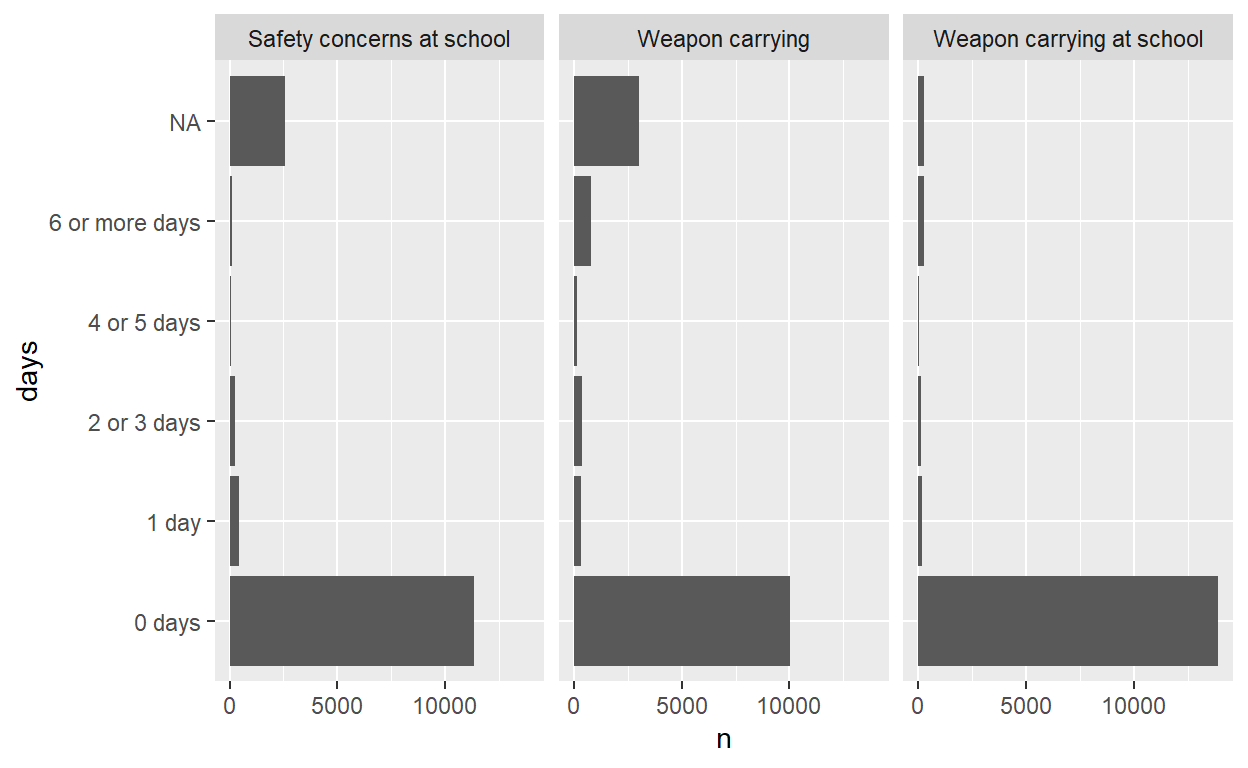
Figure 5: Bar plot 2 displays variable labels and value labels
Other packages and haven_labelled objects
It is probably safe to assume that most packages you work with don’t know how to handle the haven_labelled class - if the package does produce a result, it is likely making an educated guess which may not be in line with your needs.
For example, in using ggplot for Figure 4 above, I included the line y = factor(days); if instead I had y = days in Figure 4, ggplot yields the following message:
Don’t know how to automatically pick scale for object of type haven_labelled/vctrs_vctr/double. Defaulting to continuous.
Treating the days variable as continuous resulted in an uninformative plot (not shown), which was corrected by converting the variable to factor.
What about other packages I use? In skimr 2.1.3 haven_labelled inputs result in value codes treated as numeric values. In gtsummary ≥1.4.0 the value labels of haven_labelled variables are ignored and the underlying values are shown; however, a helpful message is printed with instructions to convert or remove the value labels. In general, you will probably find a mix of messages, warnings, errors, omissions, or guessing when using haven_labelled variables with other packages. These issues can be resolved by converting the haven_labelled variables to numeric or factor, depending on the context.
Workflow for labelled data manipulation
When converting haven_labelled objects to factor or numeric, be intentional about where the conversion happens in your workflow. The Introduction to labelled vignette by Joseph Larmarange outlines two different approaches:
First convert
haven_labelledvariables; second perform data manipulation utilizing variable labels (if factor).First perform data manipulation utilizing variable codes; second convert
haven_labelledvariables.
For me this question usually distills down to: for data manipulation, are the value codes or the value labels easier to work with? Sometimes the brevity of the value code helps (i.e., q12 == 1), whereas other times the context of the value label makes the code more readable (i.e., q12 == "0 days"). Note that the placement of the conversion can have downstream effects on your code.
Summary
The haven, labelled, sjlabelled packages create new structures and work flows for labelled data that allow you to harness the power of R while still honoring the valuable metadata framework that exists in SPSS, SAS, and Stata data sets. The functions discussed in this post cover most of my daily needs with labelled data; if you want to do more, next steps might include handling specific types of coded missing data or creating labelled data within R.
Acknowledgments
Thanks to Daniel Sjoberg for the gentle nudge to update this post. 🤗